1. RAG란?
- Retrieval-Augmented Generation(검색 증강 생성)의 약자
- LLM의 한계를 보완 → 답변의 정확성과 신뢰도를 높이는 기술
- LLM이 자체적으로 학습한 데이터 + 외부 최신 정보나 특정 전문 지식을 직접 참조하기 때문
가. 탄생 배경 - 기존 LLM의 한계
1) 환각(Hallucination)
- LLM의 가장 큰 문제점 → 학습한 데이터에 없는 내용을 사실인 것처럼 그럴듯하게 지어내는 환각 현상
- 모델의 답변에 대한 신뢰도를 심각하게 저해함
2) 지식 단절(최신화x)
- LLM은 특정 시점까지의 데이터로 학습됨
- 때문에 이후에 발생한 사건이나 정보들에 대해서는 전혀 대답하지 못 함
3) 전문성과 특수성의 부재
- LLM은 일반적이고 방대한 데이터로 학습됨
- 때문에 특정 기업의 내부적인 데이터나, 특정 전문 분야의 깊이 있는 지식에 접근하기가 어려움
- 특히, 의료 & 법률 & 금융 등 정확성과 신뢰도가 생명이 분야에서 이를 활용하기에는 위험 부담이 컸음
4) 출처 제시 부족
- 어떠한 정보를 근거로 답변을 만들었는지 출처를 정확히 제시하지 못 함
- 최근에는 출처를 명시하는 모델들이 많아지는 추세
- 때문에 사용자는 답변을 검증할 방법이 없이 그저 믿고 써야 함
나. 탄생 배경 - RAG 제시
- 페이스북 AI 연구소에서, RAG의 개념을 공식적으로 제시
- 기존의 언어 모델(생성)에 정보 검색(Retrieval) 메커니즘을 결합하는 혁신적인 프레임워크를 새롭게 제안함
- 환각은 검색된 사실 기반 정보를 통해 크게 줄일 수 있다.
- 최신 정보는 실시간으로 업데이트되는 외부 데이터베이스를 참조하여 반영할 수 있다.
- 전문 지식은 해당 분야의 데이터베이스를 연결하여 확보할 수있다.
- 답변의 근거는 참조한 외부 정보의 출처를 함께 제시함으로써 투명하게 만들 수 있다.
💡 [논문 정보]
- 논문명 : Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- 논문 링크 : https://proceedings.neurips.cc/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf
- 논문 리뷰 : [논문리뷰] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
참고 : RAG의 짧은 역사 훑어보기(첫 논문부터 최근 동향까지)
2. RAG의 작동 원리
💡 RAG는 크게 검색과 생성이라는 두 단계로 나뉘지만, 세부적으로는 아래 0~4단계 과정을 거쳐 작동한다.
📌 0단계 : 데이터 준비
가. 문서 로드 (Document Loading)
- 모든 과정의 시작은 RAG가 학습하고 참조할 지식의 원천, 즉 원본 데이터를 확보하는 것이다.
- 이러한 데이터는 다양한 형태로 존재할 수 있는데, PDF 형식의 연구 논문, 기업 내부의 Wiki 페이지, Word나 PowerPoint 형식의 업무 문서, 웹사이트의 기사, 또는 정형화된 데이터베이스의 텍스트 필드 등이 모두 해당된다.
- 시스템은
도큐먼트 로더(Document Loader)라는 특수한 컴포넌트를 사용하여 이러한 각기 다른 형식의 파일들을 읽어 들여, 시스템이 처리할 수 있는 표준화된 텍스트 형식으로 변환한다.
나. 청킹 (Chunking)
- 로드된 문서는 보통 내용이 길고 여러 주제를 한 번에 다루기 때문에, 그대로 처리하기에는 비효율적이다.
청킹은 긴 문서를 의미적으로 일관된 작은 단위, 즉청크(Chunk)로 분할하는 과정이며, 이는 검색의 정확성과 효율성을 극대화하기 위한 전략이다.- 만약 문서를 나누지 않고 통째로 벡터화한다면, 그 벡터는 문서 내의 모든 주제를 어설프게 평균 낸 ‘희석된’ 의미를 갖게 된다.
다. 임베딩 (Embedding)
- 청킹이 완료되면, 각각의 텍스트 조각(청크)은 이제 컴퓨터가 의미를 계산할 수 있는 수학적인 형태로 변환될 준비를 마친다.
임베딩은 사전 학습된 언어 모델(Embedding Model)을 사용하여 각 청크를 고차원의 숫자 벡터로 변환하는 과정이다.- 이 단계에서 생성된 벡터의 품질이 곧 RAG 시스템 검색 성능의 핵심이 되므로, 어떤 임베딩 모델을 선택하는지는 매우 중요한 결정이다.
라. 인덱싱 및 저장 (Indexing & Storing)
- 위 과정을 통해서 얻은 수많은
(벡터, 원본 청크 텍스트)쌍들은 이제 신속한 검색이 가능한 형태로 벡터 데이터베이스(Vector DB)에 저장되어야 한다.- 때문에 벡터 DB는
인덱싱(Indexing)이라는 특별한 최적화 작업을 수행한다.
- 때문에 벡터 DB는
- HNSW(Hierarchical Navigable Small World)와 같은 알고리즘을 사용하여, 벡터들 간의 관계망을 미리 계층적으로 구성해 둔다.
- 이 인덱싱 과정 덕분에, 사용자의 질문이 들어왔을 때 전체 데이터를 일일이 비교하는 대신, 압도적으로 빠른 속도로 가장 관련성 높은 청크를 찾아낼 수 있게 된다.
📌 1단계 : 질문 분석 및 변환 (Query Processing)
- 예를 들어, 사용자가 “RAG 기술의 장점이 뭐야?” 라고 질문한다.
- 시스템은 해당 질문의 의미를 컴퓨터가 이해할 수 있는 숫자 형태의 벡터(Vector)로 변환한다.
- 이러한 과정을
임베딩이라고 부르며, 질문에 담긴 핵심 의미와 의도가 벡터 안에 압축된다.
- 이러한 과정을
벡터(Vector)
- 컴퓨터는 사과, 자동차 등의 단어 의미를 인간처럼 이해하지 못 한다.
- 때문에 단어나 문장의 의미를 숫자의 배열(좌표)로 표현하며, 이를
벡터라고 부른다.
- 때문에 단어나 문장의 의미를 숫자의 배열(좌표)로 표현하며, 이를
- 2차원 지도의 경우에는, 위도 37.5 & 경도 127.0 과 같이 위치를 표현한다.
- 벡터는 여기서 차원의 개수가 수백 ~ 수천 개로 확장된
고차원 의미 공간(High-dimensional Semantic Space)의 좌표라고 보면 된다. - 각 숫자(위도 or 경도 등)는 단어가 가진 미묘한 의미의 한 부분을 나타낸다.
- 벡터는 여기서 차원의 개수가 수백 ~ 수천 개로 확장된
의미적 유사도(Semantic Similarity)
- 벡터 공간에서 두 벡터 사이의 거리는 곧 두 단어 또는 문장 사이의
의미적 유사도를 의미한다. 유사하면 가깝고, 그렇지 않다면 멀다. - 유사도를 계산할 때, 보통
코사인 유사도 방식을 사용한다.
계산 방식
1. 코사인 유사도 (Cosine Similarity)
- 두 벡터가 이루는
각도를 측정한다. - 벡터의 크기(문서의 길이 등)는 무시하고 오직 의미의
방향성에만 집중한다. - 주요 사용 사례 : RAG, 텍스트 검색, 문서 유사도 비교 등 의미적 유사성을 파악하는 데 가장 널리 사용된다.
2. 유클리드 거리 (Euclidean Distance)
- 두 벡터의 끝 점 사이를 잇는
최단 직선 거리를 측정한다. - 벡터의 방향과 크기를 모두 고려한다.
- 저차원 데이터에서는 직관적이지만, 텍스트와 같은 고차원 데이터에서는 왜곡이 발생할 수 있다.
- 주요 사용 사례 : 이미지 색상 분석, 데이터 클러스터링(군집화)
3. 내적 (Dot Product)
- 두 벡터의 방향성과 크기를 모두 곱한 값이다.
- 방향(취향)이 비슷하면서도 선호도(크기)가 강하게 나타나는 경우를 함께 포착할 수 있다.
- 주요 사용 사례 : 추천 시스템(사용자 선호도 및 평점 강도 동시 고려), 성능이 중요한 검색 시스템
4. 자카드 유사도 (Jaccard Similarity)
- 두 집합의 합집합에서 교집합이 차지하는 비율을 측정한다.
- 벡터가 아닌
집합을 대상으로 하며, 의미가 아닌 원소(단어) 자체의 중복도를 본다. - 주요 사용 사례 : 표절 검사, 구매 목록 기반 상품 추천, 중복 데이터 제거
| 계산 방법 | 대상 | 핵심 개념 | 가장 적합한 사용 사례 |
|---|---|---|---|
| 코사인 유사도 | 벡터 | 각도 (방향) | RAG, 텍스트 검색 (의미 중심) |
| 유클리드 거리 | 벡터 | 직선 거리 (방향+크기) | 이미지 분석, 클러스터링 |
| 내적 | 벡터 | 방향과 크기의 곱 | 추천 시스템 (선호도+강도), 성능 최적화 |
| 자카드 유사도 | 집합 | 원소의 중복도 (교집합/합집합) | 표절 검사, 상품 추천 (기록 기반) |
📌 2단계 : 정보 검색 (Retrieval)
- 이제 시스템은 질문과 관련된 정보를 찾기 위해 외부 자료를 찾아본다.
- 벡터와 가장 의미적으로 유사한 정보를, 미리 준비된 지식 베이스인
벡터 데이터베이스(Vector DB)에서 찾는다. - 여기에는 수많은 문서나 데이터가 질문처럼 숫자 벡터 형태로 저장되어 있다.
- 벡터와 가장 의미적으로 유사한 정보를, 미리 준비된 지식 베이스인
- 질문 벡터와 가장 가까운 거리에 있는 문서 벡터 몇 개를 후보로 가져온다. 예를 들어, RAG의 장점을 설명한 여러 문서 조각(Passage)들을 찾아내는 것이다.
- 여기서 가져올 문서의 개수는,
Top-k값을 통해서 지정할 수 있다. - 만약, Top-k 값이 3이라면 유사도가 높은 순으로 상위 3개의 문서만 가져와 참조하는 것이다.
- Top-k 값이 너무 높다면, 관련성이 떨어지는 문서들(=노이즈)가 함께 포함될 가능성이 커져서 LLM이 핵심을 놓칠 우려가 존재한다.
- 여기서 가져올 문서의 개수는,
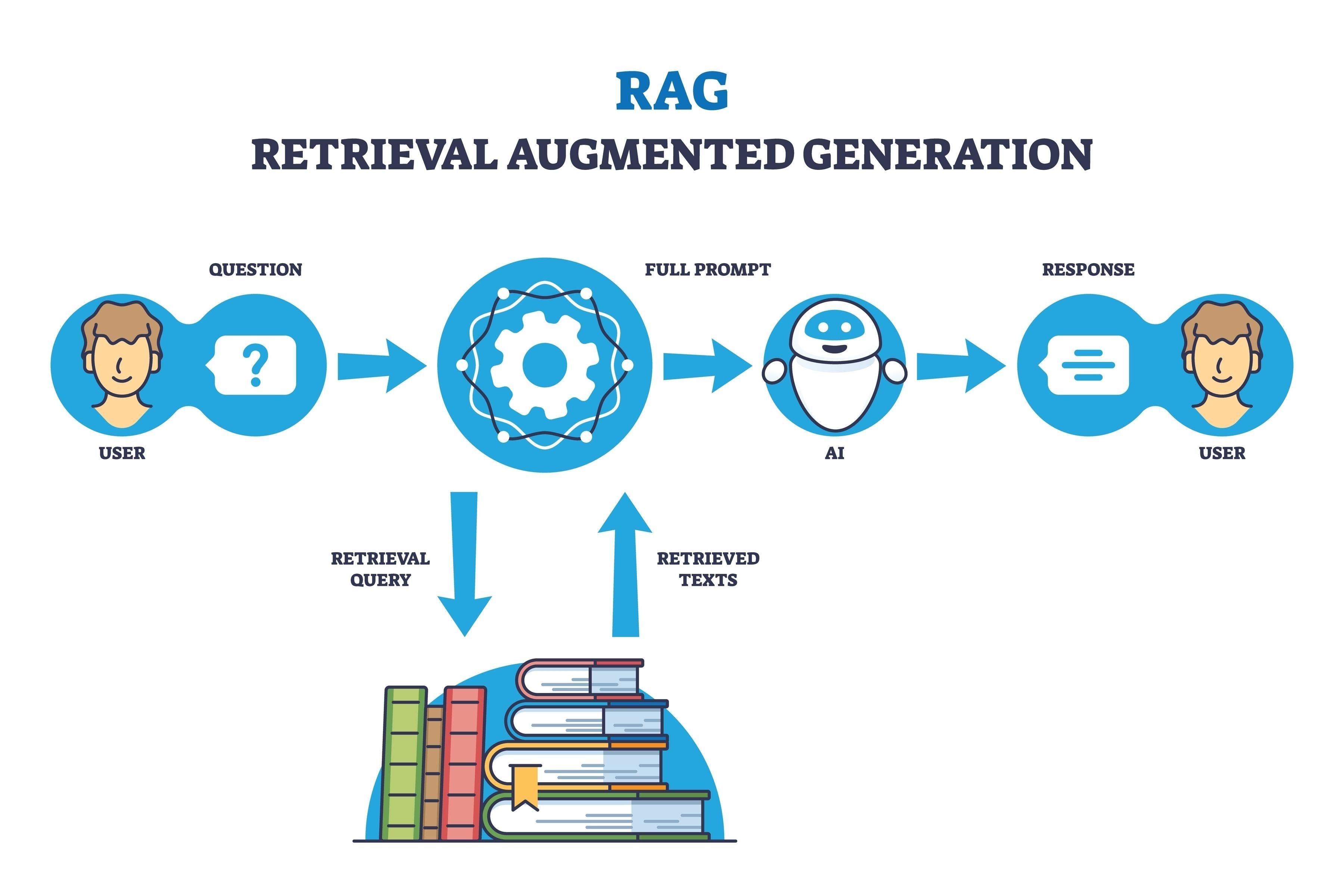
📌 3단계 : 정보 보강 및 전달 (Augmentation)
- 이 단계는 검색된 정보를 바탕으로
대규모 언어 모델(LLM)에게 줄 ‘오픈북 시험지’를 만드는 과정과 같다. - 단순히 질문만 던지는 것이 아니라, 정답을 찾기 위해 필요한 모든 참고 자료와 명확한 지시사항을 하나의 패키지로 묶어 전달하는 것이 핵심이며, 이 패키지를
프롬프트(Prompt)라고 부른다.
프롬프트의 구성 요소
- 잘 만들어진 RAG 프롬프트는 보통 다음과 같은 세 가지 주요 요소로 구성된다.
- 시스템 프롬프트 (System Prompt) 또는 지시문 (Instruction)
- LLM의 역할과 행동 원칙을 정의하는 부분으로, “반드시 아래 ‘참고 자료’에 있는 내용만을 근거로 답변해야 해”, “만약 참고 자료에 답이 없다면, ‘정보가 부족하여 답변할 수 없습니다’라고 말해” 와 같이 구체적인 규칙을 설정할 수 있다.
- 문맥 (Context) 또는 참고 자료 (Retrieved Chunks) :
- 앞선 검색 단계에서 찾아온 관련성 높은 정보 조각(청크)들이다.
- “참고 자료 1: …”, “참고 자료 2: …” 와 같은 형태로 명확하게 구분하여 LLM이 참조할 데이터임을 알려줄 수 있다.
- 사용자 질문 (User’s Question) : 사용자가 입력한 원래 질문을 마지막에 포함하여, LLM이 최종적으로 해결해야 할 과제가 무엇인지 명확히 알려준다.
- 시스템 프롬프트 (System Prompt) 또는 지시문 (Instruction)
☝🏻 예시
[System Prompt] 당신은 IT 기술에 대해 설명하는 전문 어시스턴트입니다. 아래에 제공되는 [참고 자료]를 기반으로만 답변해야 합니다. 자료에 없는 내용은 절대로 언급하지 마세요.
[참고 자료]
- (청크 1) RAG는 LLM이 최신 정보를 반영하지 못하는 한계를 극복합니다. 벡터 DB에 최신 뉴스를 계속 추가하면 LLM은 이를 참조하여 새로운 사실에 대해 답변할 수 있습니다.
- (청크 2) RAG를 사용하면 LLM 전체를 재학습시키는 파인튜닝에 비해 훨씬 적은 비용으로 모델의 지식을 업데이트할 수 있어 경제적입니다.
[사용자 질문] RAG 기술의 장점이 뭐야?
📌 4단계 : 답변 생성 (Generation)
- 마지막으로, 이 ‘오픈북 시험지’를 받은 LLM이 최종 답변을 작성하는 단계이다.
LLM의 사고 과정
- LLM은 방대한 언어 능력을 바탕으로 아래와 같은 사고 과정을 거친다.
- 지시 이해 : 먼저 시스템 프롬프트를 읽고 자신의 역할과 규칙(오직 참고 자료만 사용할 것)을 인지한다.
- 문맥 파악 : 제공된 참고 자료(청크 1, 청크 2)의 내용을 깊이 있게 이해한다.
- 질문 분석 : 사용자의 질문(“RAG 기술의 장점”)의 핵심 의도를 파악한다.
- 정보 종합 및 생성 : 이제 LLM은 자신의 사전 학습된 글쓰기 능력과 문장 구성 능력을 활용하여, 오직 참고 자료에 있는 정보만을 재료로 사용자의 질문에 대한 답변을 조합하고 생성한다.
3. RAG의 장단점
🏆 RAG의 장점
1. 정확성 향상 및 환각(Hallucination) 억제
- RAG의 가장 큰 장점으로, LLM이 학습 데이터에만 의존해 사실이 아닌 정보를 그럴듯하게 꾸며내는 ‘환각(Hallucination)’ 현상을 크게 줄일 수 있다.
- 외부의 검증된 최신 정보를 바탕으로 답변하므로, 답변의 사실성과 정확도가 극적으로 향상됩니다.
2. 최신 정보 반영
기존 일반적인 LLM과 다르게, RAG는 실시간으로 업데이트되는 외부 데이터베이스(뉴스, 기업 내부 문서 등)를 참조할 수 있으므로, 최신 정보를 반영한 답변을 생성할 수 있다.
3. 비용 효율적인 지식 업데이트
- 특정 분야의 새로운 지식을 가르치기 위해 LLM 전체를 재학습(Re-training)하거나 파인튜닝(Fine-tuning)하는 것은 막대한 비용과 시간이 소요된다.
- 그에 비해 RAG는 외부 데이터베이스에 새로운 문서만 추가하면 되므로, 훨씬 저렴하고 빠르게 최신 지식을 업데이트할 수 있다.
4. 투명성 및 신뢰도 확보
- RAG는 답변을 생성할 때 어떤 문서를 참조했는지 출처(Citation)를 제시할 수 있다.
- 사용자는 이 근거를 직접 확인하며 답변을 신뢰할 수 있고, 개발자는 답변이 잘못되었을 경우 어떤 정보 때문에 문제가 발생했는지 추적하고 디버깅하기 용이하다.
5. 특정 도메인 지식 활용
- 기업의 내부 데이터, 법률 판례, 의료 논문 등 일반적인 LLM이 학습하지 못한 특정 전문 분야의 지식을 시스템에 통합하여 전문가 수준의 답변을 제공할 수 있다.
🚧 RAG의 단점
1. 검색 성능에 대한 높은 의존도
- RAG의 성능은 전적으로 검색(Retrieval)의 품질에 달려있다.
- 만약 검색 단계에서 사용자의 질문과 관련 없거나 품질이 낮은 정보를 가져온다면, LLM은 이러한 Garbage Information을 바탕으로 오히려 더 나쁜 품질의 답변을 생성하게 된다.
2. 복잡한 파이프라인과 개발 난이도
- 단순히 LLM만 사용하는 것에 비해,
문서 로드 → 청킹 → 임베딩 → 인덱싱 → 검색등 여러 단계로 구성된 복잡한 파이프라인을 구축하고 최적화해야 한다. - 이는 개발과 유지보수에 더 많은 리소스를 필요로 한다.
3. 응답 속도 지연 (Latency)
- 사용자 질문이 들어왔을 때, LLM이 바로 답변을 생성하는 것이 아니라 ‘벡터 DB 검색’이라는 단계를 추가로 거쳐야 하기에, 순수한 LLM 호출에 비해 응답 속도가 다소 느려질 수 있다.
4. 까다로운 청킹(Chunking) 전략
- 문서를 어떻게 의미 있는 단위(청크)로 잘 나눌 것인가는 RAG 성능에 큰 영향을 미치는 어려운 문제이다.
- 너무 작게 나누면 문맥이 사라지고, 너무 크게 나누면 검색 정확도가 떨어집니다. 그렇기에 문서의 종류와 내용에 맞는 최적의 청킹 전략을 찾는 데 많은 실험이 필요하다.
4. 파라미터 및 용어 정리
RAG (검색 증강 생성): 외부 지식을 실시간으로 검색(Retrieval)하여 LLM이 답변을 생성(Generation)하게 하는 기술 프레임워크.LLM (대규모 언어 모델): 방대한 텍스트로 사전 학습된, 인간의 언어를 이해하고 구사하는 거대한 인공지능 모델.환각 (Hallucination): LLM이 사실과 다르거나 근거 없는 정보를 사실인 것처럼 꾸며내는 오류 현상.검색 (Retrieval): 사용자의 질문과 의미적으로 가장 유사한 정보를 외부 지식 소스에서 찾아오는 단계.생성 (Generation): 검색된 정보와 사용자 질문을 바탕으로 LLM이 최종 답변을 문장으로 만들어내는 단계.문서 로드 (Document Loading): PDF, 웹페이지 등 다양한 소스 문서를 시스템이 처리할 수 있는 텍스트 형태로 불러오는 과정.청킹 (Chunking): 긴 문서를 검색 및 임베딩에 적합하도록 의미 있는 작은 단위(청크)로 분할하는 데이터 전처리 작업.청크 (Chunk): 청킹을 통해 분할된 텍스트의 작은 조각이자, RAG에서 처리하는 정보의 기본 단위.청크 사이즈 (Chunk Size): 하나의 청크를 구성할 글자 또는 토큰의 최대 크기를 지정하는 파라미터.임베딩 (Embedding): 텍스트(청크, 질문 등)를 컴퓨터가 의미를 계산할 수 있는 고차원의 숫자 배열(벡터)로 변환하는 과정.벡터 (Vector): 텍스트의 의미적 정보를 담고 있는 긴 숫자 배열로, 의미 공간에서의 좌표 역할을 함.벡터 데이터베이스 (Vector DB): 대량의 벡터를 저장하고, 특정 벡터와 유사한 벡터를 초고속으로 검색하는 데 특화된 데이터베이스.인덱싱 (Indexing): 벡터 DB가 수많은 벡터들을 빠르게 검색할 수 있도록, 효율적인 데이터 구조(색인)를 미리 생성하는 작업.HNSW: 벡터 인덱싱에 널리 사용되는 알고리즘의 한 종류로, 빠르고 정확한 근사 근접 이웃 검색을 지원함.의미적 유사도 (Semantic Similarity): 두 텍스트가 의미적으로 얼마나 비슷한지를 나타내는 척도로, 주로 벡터 간의 거리나 각도로 측정함.코사인 유사도 (Cosine Similarity): 두 벡터가 이루는 각도를 이용해 유사도를 측정하는 방식으로, RAG에서 가장 보편적으로 사용됨.Top-k: 질문과 가장 유사한 상위 ‘k’개의 결과를 검색하도록 지정하는 파라미터.프롬프트 (Prompt): LLM에게 원하는 작업을 명확하게 지시하기 위해 전달하는 모든 입력값(지시문, 문맥, 질문 등).시스템 프롬프트 (System Prompt): LLM의 역할, 톤, 행동 규칙을 사전에 정의하는 프롬프트 내의 핵심 지시문.문맥 (Context): LLM이 답변 생성 시 직접적으로 참조해야 할 정보로, RAG에서는 검색된 청크들이 해당됨.출처 (Citation): 생성된 답변이 어떤 원본 문서를 근거로 했는지 출처를 명시하여 신뢰도를 높이는 기능.파인튜닝 (Fine-tuning): 사전 학습된 LLM을 특정 데이터로 추가 학습시켜 모델 자체의 파라미터를 미세 조정하는 과정.응답 속도 (Latency): 사용자가 질문한 순간부터 시스템이 최종 답변을 주기까지 걸리는 총 시간.